언어/Python
Pandas.2
implement
2023. 1. 18. 12:00
728x90

데이터프레임
시리즈는 단일 변수의 관측값 기록하기에 적합하지만 여러 변수에는 적합하지 않음 따라서 데이터프레임을 사용하는 것이 효율적
2.1.1. 딕셔너리 구조로 데이터프레임 생성
DataFrame() 메서드에 딕셔너리 구조를 넘겨주며 생성
df = pandas.DataFrame({'A' : [1, 2, 3, 4],
'B' : [11, 12, 13, 14]}, index = [2000, 2001, 2002, 2003]) #index는 없어도 됨
print(df)
2.1.2. 시리즈로 데이터프레임 생성
DataFrame()의 생성자로 시리즈의 이름과 시리즈를 딕셔너리 형태로 넘겨주며 생성
a = pandas.Series([1, 2, 3, 4], index = [2000, 2001, 2002, 2003], name = 'A')
b = pandas.Series([11, 12, 13, 14], index = [2000, 2001, 2002, 2003], name = 'B')
df = pandas.DataFrame({a.name: a, b.name: b})
print(df)생성 시 인덱스는 오름차순으로 정렬되며, 인덱스에 해당하는 값이 없을 경우 NaN으로 표시됨.
2.1.3. 리스트로 데이터프레임 생성
리스트로 한 행씩 추가할 수 있다.
name = ['A', 'B']
index = [2000, 2001, 2002, 2003]
row = []
row.append([1, 11])
row.append([2, 12])
row.append([3, 13])
row.append([4, 14])
df = pandas.DataFrame(v, columns=name, index=index)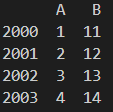
2.2. 데이터프레임 순회
일반적으로 itertuples()가 iterrows()보다 빠르다고 알려져 있다.
for i in df.index:
print(i, df['A'][i], df['B'][i])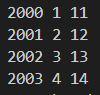
for row in df.itertuples(name = 'ab'):
print(row)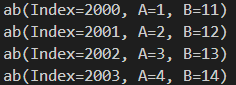
for row in df.itertuples():
print(row[0], row[1], row[2])for idx, row in df.iterrows():
print(idx, row[0], row[1])
반응형