언어/Python
Pandas.1
implement
2023. 1. 15. 12:00
728x90

pandas는 넘파이 기반의 데이터 처리를 위한 파이썬 라이브러리이다. 구조화된 데이터를 쉽고 빠르게 가공할 수 있는 자료형과 함수를 제공한다.
0.1. padas 설치
pip install pandas
1.1. 시리즈 생성
Series()에 리스트 형태의 생성자를 넘겨주면 생성할 수 있다.
s = pandas.Series([0.0, 1.0, 2.0, 3.0])
print(s)
1.2. 인덱스 변경
Index()에 리스트 형태의 생성자를 넘겨주어 변경할 수 있다.
s.index = pandas.Index([4.0, 5.0, 6.0, 7.0])
print(s)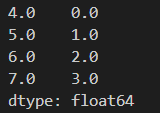
1.3. 인덱스명, 시리즈명 설정
name속성으로 변경할 수 있다.
s.index.name = “인덱스명”
s.name = “시리즈명”
1.4. 데이터 추가
데이터를 하나만 추가하는 경우 []를 이용하여, 다른 시리즈를 기존의 시리즈에 추가하는 경우 append() 메서드로 추가 할 수 있다.
s[8.0] = 4.0
s2 = pandas.Series([1.11, 2.22])
s2.index = pandas.Index([333.3, 444.4]) #새로운 시리즈 생성
s = s.append(s2)
1.5 데이터 탐색
1.5.1 인덱스의 순서로 찾는 방법
s.index[i] #i번째 인덱스
s.values[i] #i번째 값
s.iloc[i] #i번째 값values와 iloc의 차이
결과값이 복수개 일 경우 values는 배열로 반환하고 iloc는 시리즈로 반환함


1.5.2 인덱스로 찾는 방법
s.loc[i] #인덱스 i에 있는 값 출력
#EX#
s.loc[4.0] # == 0.0
1.6. 데이터 삭제
drop() 메서드의 인수에 인덱스값을 넘겨주어 삭제
s.drop(i) #i는 인덱스값
s.drop(s.index(i)) #i번째 인덱스
1.7. 시리즈 정보 보기
describe() 메서드를 사용. 원소 개수, 평균, 표준편차, 최솟값, 제1 사분위수, 제2 사분위수, 제3 사분위수, 최댓값등의 정보를 나타냄.
s.describe()
반응형